The A - Z Guide Of Deepseek
페이지 정보
작성자 Erna 작성일 25-02-01 06:51 조회 7 댓글 0본문
A standout feature of DeepSeek LLM 67B Chat is its outstanding performance in coding, achieving a HumanEval Pass@1 rating of 73.78. The model also exhibits distinctive mathematical capabilities, with GSM8K zero-shot scoring at 84.1 and Math 0-shot at 32.6. Notably, it showcases an impressive generalization potential, evidenced by an outstanding score of 65 on the challenging Hungarian National Highschool Exam. The mannequin's coding capabilities are depicted within the Figure under, the place the y-axis represents the pass@1 score on in-domain human evaluation testing, and the x-axis represents the go@1 rating on out-domain LeetCode Weekly Contest problems. The transfer signals DeepSeek-AI’s commitment to democratizing entry to advanced AI capabilities. Reported discrimination against sure American dialects; varied teams have reported that unfavorable changes in AIS look like correlated to using vernacular and this is very pronounced in Black and Latino communities, with numerous documented circumstances of benign question patterns leading to decreased AIS and due to this fact corresponding reductions in access to powerful AI providers.
 Warschawski will develop positioning, messaging and a new web site that showcases the company’s subtle intelligence services and global intelligence expertise. The open supply DeepSeek-R1, as well as its API, will profit the research group to distill higher smaller fashions in the future. I am proud to announce that we've reached a historic agreement with China that can benefit each our nations. ArenaHard: The mannequin reached an accuracy of 76.2, compared to 68.Three and 66.3 in its predecessors. Based on him DeepSeek-V2.5 outperformed Meta’s Llama 3-70B Instruct and Llama 3.1-405B Instruct, however clocked in at below efficiency compared to OpenAI’s GPT-4o mini, Claude 3.5 Sonnet, and OpenAI’s GPT-4o. Often, I discover myself prompting Claude like I’d prompt an extremely high-context, patient, not possible-to-offend colleague - in other words, I’m blunt, quick, and communicate in a lot of shorthand. BYOK clients should test with their provider in the event that they assist Claude 3.5 Sonnet for his or her particular deployment setting. While particular languages supported are usually not listed, DeepSeek Coder is educated on a vast dataset comprising 87% code from multiple sources, suggesting broad language help. Businesses can combine the model into their workflows for numerous tasks, ranging from automated customer assist and content generation to software program growth and data analysis.
Warschawski will develop positioning, messaging and a new web site that showcases the company’s subtle intelligence services and global intelligence expertise. The open supply DeepSeek-R1, as well as its API, will profit the research group to distill higher smaller fashions in the future. I am proud to announce that we've reached a historic agreement with China that can benefit each our nations. ArenaHard: The mannequin reached an accuracy of 76.2, compared to 68.Three and 66.3 in its predecessors. Based on him DeepSeek-V2.5 outperformed Meta’s Llama 3-70B Instruct and Llama 3.1-405B Instruct, however clocked in at below efficiency compared to OpenAI’s GPT-4o mini, Claude 3.5 Sonnet, and OpenAI’s GPT-4o. Often, I discover myself prompting Claude like I’d prompt an extremely high-context, patient, not possible-to-offend colleague - in other words, I’m blunt, quick, and communicate in a lot of shorthand. BYOK clients should test with their provider in the event that they assist Claude 3.5 Sonnet for his or her particular deployment setting. While particular languages supported are usually not listed, DeepSeek Coder is educated on a vast dataset comprising 87% code from multiple sources, suggesting broad language help. Businesses can combine the model into their workflows for numerous tasks, ranging from automated customer assist and content generation to software program growth and data analysis.
The model’s open-source nature also opens doors for further research and growth. "DeepSeek V2.5 is the precise finest performing open-source mannequin I’ve examined, inclusive of the 405B variants," he wrote, additional underscoring the model’s potential. This is cool. Against my non-public GPQA-like benchmark deepseek v2 is the precise best performing open source model I've tested (inclusive of the 405B variants). Among open fashions, we've seen CommandR, DBRX, Phi-3, Yi-1.5, Qwen2, DeepSeek v2, Mistral (NeMo, Large), Gemma 2, Llama 3, Nemotron-4. This enables for more accuracy and recall in areas that require an extended context window, along with being an improved version of the previous Hermes and Llama line of models. DeepSeek, the AI offshoot of Chinese quantitative hedge fund High-Flyer Capital Management, has officially launched its latest mannequin, DeepSeek-V2.5, an enhanced version that integrates the capabilities of its predecessors, DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724. 1. The bottom models have been initialized from corresponding intermediate checkpoints after pretraining on 4.2T tokens (not the model at the tip of pretraining), then pretrained additional for 6T tokens, then context-prolonged to 128K context length.
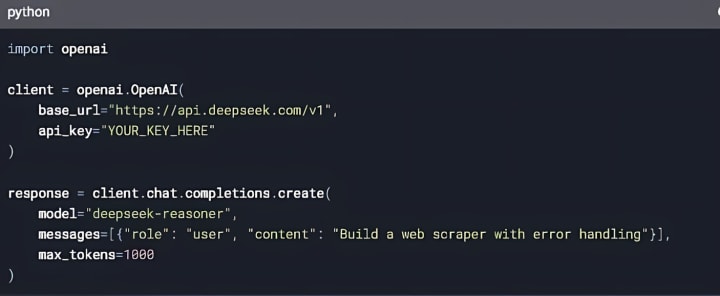 2. Long-context pretraining: 200B tokens. Fact: In a capitalist society, people have the liberty to pay for providers they want. Millions of individuals use tools reminiscent of ChatGPT to help them with on a regular basis duties like writing emails, summarising text, and answering questions - and others even use them to help with fundamental coding and studying. This implies you should use the know-how in industrial contexts, including selling providers that use the mannequin (e.g., software-as-a-service). Notably, the model introduces perform calling capabilities, enabling it to work together with exterior tools extra effectively. Their product allows programmers to extra easily integrate varied communication strategies into their software and applications. Things like that. That's probably not within the OpenAI DNA to this point in product. However, it may be launched on dedicated Inference Endpoints (like Telnyx) for scalable use. Yes, DeepSeek Coder helps business use below its licensing settlement. By nature, the broad accessibility of new open source AI fashions and permissiveness of their licensing means it is simpler for different enterprising builders to take them and enhance upon them than with proprietary fashions. As such, there already appears to be a brand new open supply AI model chief simply days after the final one was claimed.
2. Long-context pretraining: 200B tokens. Fact: In a capitalist society, people have the liberty to pay for providers they want. Millions of individuals use tools reminiscent of ChatGPT to help them with on a regular basis duties like writing emails, summarising text, and answering questions - and others even use them to help with fundamental coding and studying. This implies you should use the know-how in industrial contexts, including selling providers that use the mannequin (e.g., software-as-a-service). Notably, the model introduces perform calling capabilities, enabling it to work together with exterior tools extra effectively. Their product allows programmers to extra easily integrate varied communication strategies into their software and applications. Things like that. That's probably not within the OpenAI DNA to this point in product. However, it may be launched on dedicated Inference Endpoints (like Telnyx) for scalable use. Yes, DeepSeek Coder helps business use below its licensing settlement. By nature, the broad accessibility of new open source AI fashions and permissiveness of their licensing means it is simpler for different enterprising builders to take them and enhance upon them than with proprietary fashions. As such, there already appears to be a brand new open supply AI model chief simply days after the final one was claimed.
댓글목록 0
등록된 댓글이 없습니다.