What Can you Do About Deepseek Proper Now
페이지 정보
작성자 Jetta 작성일 25-02-01 12:18 조회 4 댓글 0본문
 Alternatively, you can obtain the deepseek ai china app for iOS or Android, and use the chatbot on your smartphone. The use of DeepSeek-V2 Base/Chat models is topic to the Model License. DeepSeek was the first firm to publicly match OpenAI, which earlier this yr launched the o1 class of models which use the same RL method - an extra signal of how refined DeepSeek is. The corporate costs its products and services properly under market value - and gives others away free of charge. The wonderful-tuning job relied on a uncommon dataset he’d painstakingly gathered over months - a compilation of interviews psychiatrists had carried out with patients with psychosis, as well as interviews those same psychiatrists had carried out with AI systems. I enjoy offering models and helping people, and would love to have the ability to spend much more time doing it, as well as expanding into new tasks like high-quality tuning/training. Why this matters - symptoms of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been building subtle infrastructure and training models for a few years. When the final human driver lastly retires, we can update the infrastructure for machines with cognition at kilobits/s. Read extra: Sapiens: Foundation for Human Vision Models (arXiv).
Alternatively, you can obtain the deepseek ai china app for iOS or Android, and use the chatbot on your smartphone. The use of DeepSeek-V2 Base/Chat models is topic to the Model License. DeepSeek was the first firm to publicly match OpenAI, which earlier this yr launched the o1 class of models which use the same RL method - an extra signal of how refined DeepSeek is. The corporate costs its products and services properly under market value - and gives others away free of charge. The wonderful-tuning job relied on a uncommon dataset he’d painstakingly gathered over months - a compilation of interviews psychiatrists had carried out with patients with psychosis, as well as interviews those same psychiatrists had carried out with AI systems. I enjoy offering models and helping people, and would love to have the ability to spend much more time doing it, as well as expanding into new tasks like high-quality tuning/training. Why this matters - symptoms of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been building subtle infrastructure and training models for a few years. When the final human driver lastly retires, we can update the infrastructure for machines with cognition at kilobits/s. Read extra: Sapiens: Foundation for Human Vision Models (arXiv).
![]() Read extra: The Unbearable Slowness of Being (arXiv). For extended sequence fashions - eg 8K, 16K, 32K - the required RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. The mannequin read psychology texts and constructed software program for administering character checks. There was a type of ineffable spark creeping into it - for lack of a greater word, personality. There was a tangible curiosity coming off of it - a tendency in the direction of experimentation. He knew the data wasn’t in any other techniques as a result of the journals it got here from hadn’t been consumed into the AI ecosystem - there was no trace of them in any of the training units he was conscious of, and fundamental information probes on publicly deployed fashions didn’t seem to indicate familiarity. Of course he knew that individuals may get their licenses revoked - but that was for terrorists and criminals and different unhealthy types. But in his mind he questioned if he may really be so assured that nothing unhealthy would occur to him. And in it he thought he might see the beginnings of something with an edge - a mind discovering itself by way of its own textual outputs, studying that it was separate to the world it was being fed.
Read extra: The Unbearable Slowness of Being (arXiv). For extended sequence fashions - eg 8K, 16K, 32K - the required RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. The mannequin read psychology texts and constructed software program for administering character checks. There was a type of ineffable spark creeping into it - for lack of a greater word, personality. There was a tangible curiosity coming off of it - a tendency in the direction of experimentation. He knew the data wasn’t in any other techniques as a result of the journals it got here from hadn’t been consumed into the AI ecosystem - there was no trace of them in any of the training units he was conscious of, and fundamental information probes on publicly deployed fashions didn’t seem to indicate familiarity. Of course he knew that individuals may get their licenses revoked - but that was for terrorists and criminals and different unhealthy types. But in his mind he questioned if he may really be so assured that nothing unhealthy would occur to him. And in it he thought he might see the beginnings of something with an edge - a mind discovering itself by way of its own textual outputs, studying that it was separate to the world it was being fed.
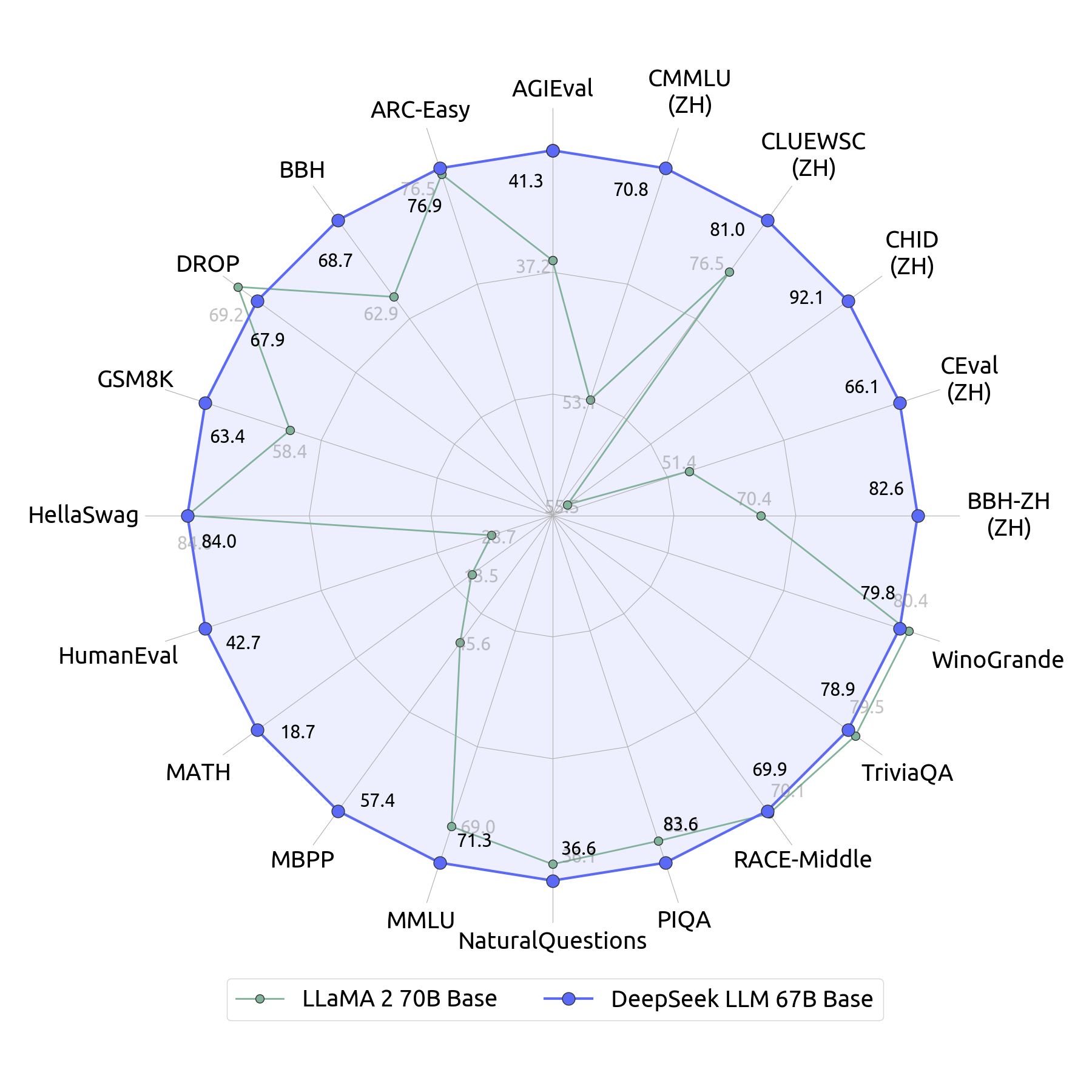
We’re thrilled to share our progress with the neighborhood and see the hole between open and closed fashions narrowing. "We estimate that in comparison with the perfect international standards, even the best home efforts face a few twofold gap when it comes to model structure and coaching dynamics," Wenfeng says. Additionally, there’s a few twofold gap in knowledge effectivity, meaning we need twice the training knowledge and computing energy to achieve comparable outcomes. Combined, this requires 4 occasions the computing energy. "This means we'd like twice the computing power to achieve the same results. "This run presents a loss curve and convergence price that meets or exceeds centralized training," Nous writes. Track the NOUS run right here (Nous DisTro dashboard). Take a look at Andrew Critch’s put up right here (Twitter). There’s no straightforward answer to any of this - everybody (myself included) wants to figure out their very own morality and strategy here. John Muir, the Californian naturist, was stated to have let out a gasp when he first saw the Yosemite valley, seeing unprecedentedly dense and love-stuffed life in its stone and trees and wildlife. K), a decrease sequence size might have for use. "The sensible information we've got accrued could prove invaluable for both industrial and tutorial sectors.
Researchers at Tsinghua University have simulated a hospital, stuffed it with LLM-powered brokers pretending to be patients and medical staff, then shown that such a simulation can be utilized to enhance the actual-world performance of LLMs on medical check exams… DeepSeek's first-era of reasoning fashions with comparable performance to OpenAI-o1, together with six dense fashions distilled from DeepSeek-R1 based mostly on Llama and Qwen. AI CEO, Elon Musk, simply went online and began trolling DeepSeek’s performance claims. DeepSeek’s system: The system is known as Fire-Flyer 2 and is a hardware and software system for doing massive-scale AI training. As DeepSeek’s founder mentioned, the only problem remaining is compute. If we get it unsuitable, we’re going to be dealing with inequality on steroids - a small caste of people will likely be getting an unlimited quantity achieved, aided by ghostly superintelligences that work on their behalf, whereas a bigger set of people watch the success of others and ask ‘why not me? The success of the company's A.I.
댓글목록 0
등록된 댓글이 없습니다.