New Questions about Deepseek Answered And Why You Need to Read Every W…
페이지 정보
작성자 Novella 작성일 25-02-01 22:31 조회 4 댓글 0본문
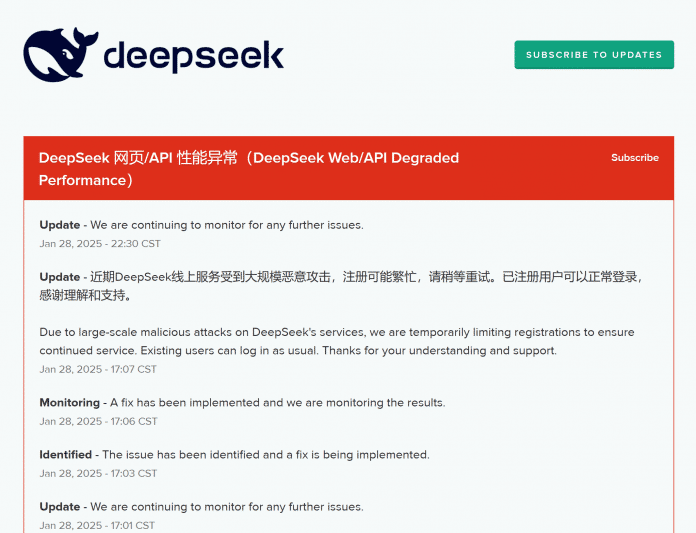
 The DeepSeek Chat V3 mannequin has a high score on aider’s code editing benchmark. The reproducible code for the following evaluation results will be discovered within the Evaluation listing. It's a must to have the code that matches it up and sometimes you'll be able to reconstruct it from the weights. The purpose of this submit is to deep-dive into LLM’s that are specialised in code generation duties, and see if we will use them to write code. You possibly can see these concepts pop up in open source where they try to - if individuals hear about a good suggestion, they try to whitewash it and then brand it as their very own. Just through that pure attrition - people depart on a regular basis, whether or not it’s by alternative or not by alternative, after which they talk. We've some rumors and hints as to the structure, simply because people discuss. They only did a reasonably massive one in January, the place some folks left. Where does the know-how and the experience of truly having worked on these fashions up to now play into having the ability to unlock the benefits of whatever architectural innovation is coming down the pipeline or appears promising within one in every of the key labs?
The DeepSeek Chat V3 mannequin has a high score on aider’s code editing benchmark. The reproducible code for the following evaluation results will be discovered within the Evaluation listing. It's a must to have the code that matches it up and sometimes you'll be able to reconstruct it from the weights. The purpose of this submit is to deep-dive into LLM’s that are specialised in code generation duties, and see if we will use them to write code. You possibly can see these concepts pop up in open source where they try to - if individuals hear about a good suggestion, they try to whitewash it and then brand it as their very own. Just through that pure attrition - people depart on a regular basis, whether or not it’s by alternative or not by alternative, after which they talk. We've some rumors and hints as to the structure, simply because people discuss. They only did a reasonably massive one in January, the place some folks left. Where does the know-how and the experience of truly having worked on these fashions up to now play into having the ability to unlock the benefits of whatever architectural innovation is coming down the pipeline or appears promising within one in every of the key labs?
 Although the deepseek-coder-instruct fashions are usually not specifically trained for code completion duties throughout supervised advantageous-tuning (SFT), they retain the aptitude to perform code completion effectively. DeepSeek Coder is a collection of code language fashions with capabilities ranging from mission-level code completion to infilling tasks. This qualitative leap in the capabilities of deepseek ai LLMs demonstrates their proficiency across a big selection of applications. The mannequin's coding capabilities are depicted within the Figure below, where the y-axis represents the move@1 rating on in-domain human analysis testing, and the x-axis represents the cross@1 rating on out-area LeetCode Weekly Contest problems. As well as, per-token probability distributions from the RL policy are in comparison with those from the preliminary mannequin to compute a penalty on the distinction between them. Also, when we talk about a few of these innovations, you need to even have a mannequin working. People just get together and discuss as a result of they went to high school together or they labored together. Because they can’t actually get a few of these clusters to run it at that scale.
Although the deepseek-coder-instruct fashions are usually not specifically trained for code completion duties throughout supervised advantageous-tuning (SFT), they retain the aptitude to perform code completion effectively. DeepSeek Coder is a collection of code language fashions with capabilities ranging from mission-level code completion to infilling tasks. This qualitative leap in the capabilities of deepseek ai LLMs demonstrates their proficiency across a big selection of applications. The mannequin's coding capabilities are depicted within the Figure below, where the y-axis represents the move@1 rating on in-domain human analysis testing, and the x-axis represents the cross@1 rating on out-area LeetCode Weekly Contest problems. As well as, per-token probability distributions from the RL policy are in comparison with those from the preliminary mannequin to compute a penalty on the distinction between them. Also, when we talk about a few of these innovations, you need to even have a mannequin working. People just get together and discuss as a result of they went to high school together or they labored together. Because they can’t actually get a few of these clusters to run it at that scale.
To what extent is there additionally tacit information, and the architecture already running, and this, that, and the other factor, in order to have the ability to run as quick as them? There’s already a hole there they usually hadn’t been away from OpenAI for that long before. And there’s just a little bit little bit of a hoo-ha round attribution and stuff. That is each an fascinating thing to observe in the abstract, and also rhymes with all the other stuff we keep seeing throughout the AI research stack - the more and more we refine these AI methods, the more they appear to have properties just like the mind, whether that be in convergent modes of illustration, comparable perceptual biases to humans, or at the hardware degree taking on the traits of an increasingly giant and interconnected distributed system. You need folks which might be hardware consultants to actually run these clusters. "Smaller GPUs current many promising hardware traits: they've a lot decrease value for fabrication and packaging, larger bandwidth to compute ratios, decrease energy density, and lighter cooling requirements". I’m unsure how much of you can steal without additionally stealing the infrastructure.
So far, though GPT-four completed training in August 2022, there is still no open-supply mannequin that even comes near the original GPT-4, a lot much less the November 6th GPT-4 Turbo that was released. That's even higher than GPT-4. OpenAI has provided some element on DALL-E 3 and GPT-4 Vision. You would possibly even have people dwelling at OpenAI that have distinctive ideas, but don’t even have the rest of the stack to assist them put it into use. So you’re already two years behind as soon as you’ve discovered learn how to run it, which is not even that easy. But I’m curious to see how OpenAI in the next two, three, four years changes. If you bought the GPT-4 weights, again like Shawn Wang stated, the model was trained two years in the past. We then prepare a reward mannequin (RM) on this dataset to foretell which mannequin output our labelers would prefer. The current "best" open-weights fashions are the Llama 3 series of fashions and Meta seems to have gone all-in to practice the very best vanilla Dense transformer. It may possibly have vital implications for purposes that require looking over an unlimited area of potential solutions and have tools to confirm the validity of model responses.
In case you have any questions relating to exactly where and tips on how to employ free deepseek ai china (photoclub.canadiangeographic.ca), it is possible to e-mail us with the website.
댓글목록 0
등록된 댓글이 없습니다.