Deepseek For Dollars
페이지 정보
작성자 Anne 작성일 25-02-01 10:56 조회 8 댓글 0본문
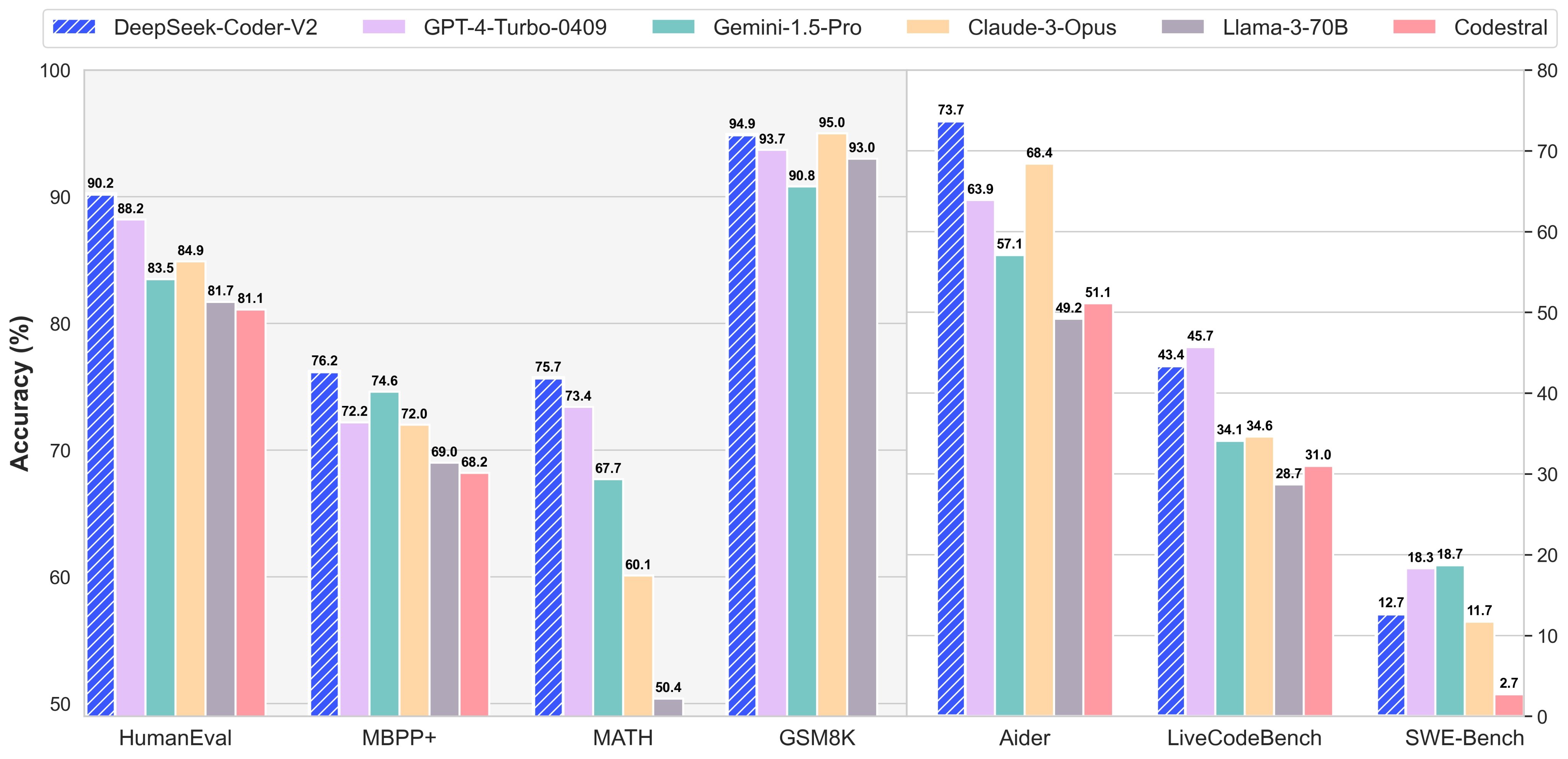 Based on DeepSeek’s inside benchmark testing, DeepSeek V3 outperforms each downloadable, "openly" available fashions and "closed" AI fashions that may only be accessed through an API. The 33b fashions can do quite a few things accurately. Applications: Like different fashions, StarCode can autocomplete code, make modifications to code by way of instructions, and even explain a code snippet in pure language. As of the now, Codestral is our present favorite mannequin capable of both autocomplete and chat. If your machine can’t handle both at the same time, then try every of them and decide whether or not you want an area autocomplete or a local chat experience. We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 coaching on an especially massive-scale mannequin. Innovations: It relies on Llama 2 mannequin from Meta by additional training it on code-specific datasets. R1 is critical because it broadly matches OpenAI’s o1 model on a range of reasoning duties and challenges the notion that Western AI corporations hold a significant lead over Chinese ones.
Based on DeepSeek’s inside benchmark testing, DeepSeek V3 outperforms each downloadable, "openly" available fashions and "closed" AI fashions that may only be accessed through an API. The 33b fashions can do quite a few things accurately. Applications: Like different fashions, StarCode can autocomplete code, make modifications to code by way of instructions, and even explain a code snippet in pure language. As of the now, Codestral is our present favorite mannequin capable of both autocomplete and chat. If your machine can’t handle both at the same time, then try every of them and decide whether or not you want an area autocomplete or a local chat experience. We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 coaching on an especially massive-scale mannequin. Innovations: It relies on Llama 2 mannequin from Meta by additional training it on code-specific datasets. R1 is critical because it broadly matches OpenAI’s o1 model on a range of reasoning duties and challenges the notion that Western AI corporations hold a significant lead over Chinese ones.
This model demonstrates how LLMs have improved for programming duties. Capabilities: StarCoder is an advanced AI mannequin specially crafted to assist software developers and programmers in their coding tasks. When you employ Continue, you mechanically generate data on the way you build software program. It is a visitor publish from Ty Dunn, Co-founding father of Continue, that covers how you can arrange, explore, and work out one of the best ways to make use of Continue and Ollama collectively. Assuming you have a chat model set up already (e.g. Codestral, Llama 3), you'll be able to keep this entire experience local due to embeddings with Ollama and LanceDB. Next, we collect a dataset of human-labeled comparisons between outputs from our fashions on a bigger set of API prompts. Models like Deepseek Coder V2 and Llama 3 8b excelled in handling superior programming ideas like generics, higher-order features, and information structures. In data science, tokens are used to signify bits of uncooked knowledge - 1 million tokens is equal to about 750,000 phrases. Some words have been taboo. This overlap ensures that, because the mannequin additional scales up, so long as we maintain a relentless computation-to-communication ratio, we can nonetheless make use of nice-grained specialists across nodes while attaining a close to-zero all-to-all communication overhead.
They minimized the communication latency by overlapping extensively computation and communication, corresponding to dedicating 20 streaming multiprocessors out of 132 per H800 for only inter-GPU communication. Period. Deepseek isn't the problem you ought to be watching out for imo. Despite the attack, DeepSeek maintained service for current customers. Until now, China’s censored internet has largely affected only Chinese customers. Chinese telephone number, on a Chinese internet connection - that means that I can be subject to China’s Great Firewall, which blocks websites like Google, Facebook and The brand new York Times. Chatbot Navigate China’s Censors? The launch of a brand new chatbot by Chinese artificial intelligence firm DeepSeek triggered a plunge in US tech stocks because it appeared to carry out as well as OpenAI’s ChatGPT and different AI fashions, however using fewer assets. Vivian Wang, reporting from behind the nice Firewall, had an intriguing dialog with deepseek ai’s chatbot. Note: English open-ended conversation evaluations. The results of my dialog stunned me. Collecting into a new vector: The squared variable is created by accumulating the results of the map operate into a new vector. The mannequin, DeepSeek V3, was developed by the AI agency deepseek ai and was released on Wednesday beneath a permissive license that allows builders to obtain and modify it for most purposes, including industrial ones.
The corporate also claims it only spent $5.5 million to prepare DeepSeek V3, a fraction of the development cost of models like OpenAI’s GPT-4. This focus permits the company to concentrate on advancing foundational AI applied sciences without rapid industrial pressures. This allows it to leverage the capabilities of Llama for coding. Benchmark assessments point out that DeepSeek-V3 outperforms models like Llama 3.1 and Qwen 2.5, while matching the capabilities of GPT-4o and Claude 3.5 Sonnet. In alignment with DeepSeekCoder-V2, we also incorporate the FIM technique within the pre-coaching of DeepSeek-V3. Auxiliary-loss-free load balancing technique for mixture-of-consultants. For the reason that MoE half only needs to load the parameters of 1 expert, the memory entry overhead is minimal, so using fewer SMs is not going to significantly affect the overall efficiency. DeepSeek-Coder-V2, an open-supply Mixture-of-Experts (MoE) code language model. Inexplicably, the model named DeepSeek-Coder-V2 Chat in the paper was launched as DeepSeek-Coder-V2-Instruct in HuggingFace. DeepSeek V3 additionally crushes the competitors on Aider Polyglot, a test designed to measure, among other things, whether a mannequin can efficiently write new code that integrates into existing code. When the final human driver lastly retires, we are able to replace the infrastructure for machines with cognition at kilobits/s.
댓글목록 0
등록된 댓글이 없습니다.